How to Secure AI Agents: Preventing Prompt Injection Attacks in Production
-
- by Fiaz Ahmad
- June 19, 2026
- in AI Agents News, AI for Developers

If you are building AI agents in 2026, understanding how to secure AI agents is no longer optional. Prompt injection attacks have surged 340 percent year over year according to OWASP’s 2026 LLM Security Report, making them the fastest-growing cyberattack category in the world. Developers who treat secure AI agents as an afterthought are leaving their entire production stack exposed to a class of risk that traditional firewalls and endpoint tools simply cannot address. This guide walks through what prompt injection actually is, why it is so difficult to defend against, and the specific defense layers enterprise teams use to secure AI agents before a single line of production code goes live.
What Is Prompt Injection and Why Does It Threaten Secure AI Agents
At its core, a prompt injection attack exploits a fundamental weakness in large language models. LLMs process everything as tokens. They have no reliable way to distinguish between a system instruction and content supplied by a user, which means an attacker who can insert text into an agent’s input stream can potentially override the operator’s directives completely.
The threat has evolved far beyond tricking a chatbot into saying something it should not. Modern AI agents browse websites, query databases, send emails, execute code, and in some deployments even approve financial transactions. A successful injection against one of these agents does not just produce a bad output. It can exfiltrate data, redirect payments, corrupt memory stores, or push malicious instructions through an entire multi-agent pipeline. For teams working to secure AI agents handling sensitive workloads, this is not a hypothetical. It is an active, documented risk.
Two primary attack types define the current threat landscape. Direct prompt injection happens when an attacker interacts with the AI system directly, embedding override instructions inside their own input. Indirect prompt injection is considerably more dangerous. Here, the attacker embeds malicious instructions inside external content such as a web page, a PDF, an email attachment, or an API response that the agent retrieves as part of a completely legitimate task. The attacker never touches the AI interface at all.
A third variant called memory poisoning plants injected instructions into the agent’s long-term memory during one session. In later sessions, those stored instructions activate as if they were legitimate system-level directives. Security researchers have documented this exact pattern in Amazon Bedrock agents surviving across session boundaries. Developers working on custom AI agent development need to account for all three attack types from the design stage, before any tool permissions are granted.
The Scale of the Problem: Key Statistics and Insights
The numbers tell a clear story. Multi-hop indirect attacks involving agents and tools increased by over 70 percent year over year between 2025 and 2026. Google’s threat intelligence team found a 32 percent increase in malicious prompt injection payloads embedded in web content between November 2025 and February 2026. Research from June 2026 showed that direct attacks against GPT-5 and Gemini-powered agents succeeded more than 79 percent of the time, confirming that even frontier models remain vulnerable without the right defensive architecture built around them.
OWASP ranks prompt injection as LLM01:2025, the top vulnerability in its Top 10 for LLM Applications for the third year running. In December 2025, OWASP released the first dedicated framework for autonomous systems: the Top 10 for Agentic Applications 2026, developed with input from over 100 security researchers and endorsed by NIST, Microsoft, and NVIDIA. The framework explicitly calls out advanced prompt injection and goal hijacking as two of the ten most critical risks facing teams that deploy and secure AI agents at scale.
About 40 percent of AI agent protocols contain vulnerabilities exploitable via prompt injection. When defense frameworks are properly layered, attack success rates drop from 73.2 percent down to as low as 8.7 percent. That gap between an undefended and a well-defended deployment is the entire business case for investing in prompt injection prevention before you scale. A 2026 industry report found that 67 percent of organizations reported AI agent security incidents in Q2 2026 alone, and 80 percent of IT professionals witnessed agents performing unauthorized actions in their production environments.
How to Secure AI Agents: A Layered Defense Framework
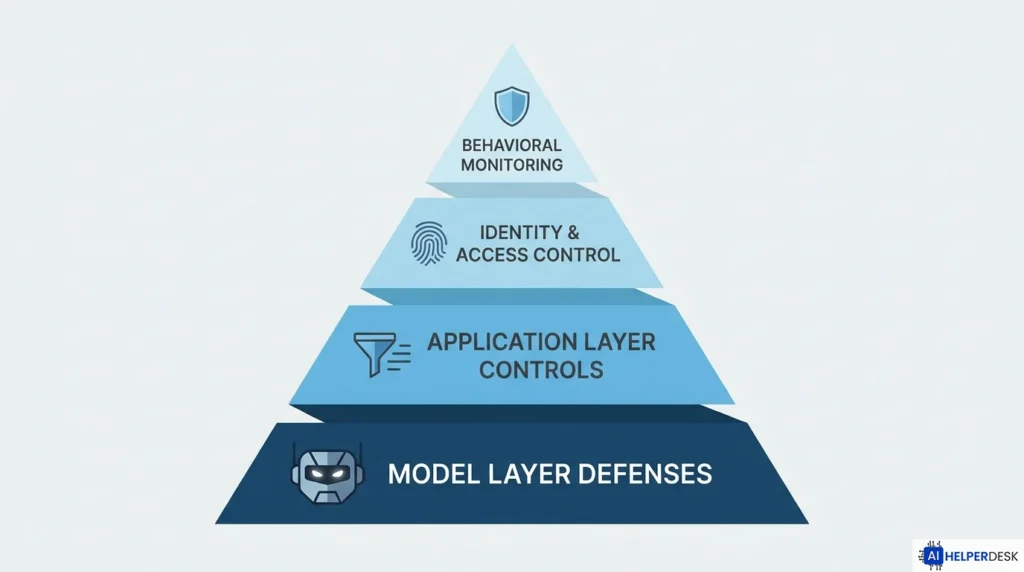
Here is the honest reality, acknowledged by OpenAI, Anthropic, and Google DeepMind in their own 2025 security publications: prompt injection cannot be fully eliminated at the model level. Any defense expressed as a prompt instruction can itself be overridden. That is a structural limitation of current LLM architectures. The goal for any team working to secure AI agents in production therefore shifts from perfect prevention to controlled blast radius. The aim is ensuring that a successful injection cannot escalate into a catastrophic compromise, because multiple layers of control limit what injected instructions can actually accomplish.
Model Layer Defenses
The first line of defense to secure AI agents starts at the model itself. Choose models with demonstrated resistance to injection attempts and update them regularly as bypass techniques evolve. Enable the built-in safety training and jailbreak resistance features your model provider offers. Model-level prompt filtering reduces the probability of simple attacks, but it is not enough on its own. Security researchers have documented 42 distinct prompt injection techniques across ecosystems, meaning any static model-level filter will have gaps that determined attackers will eventually find.
Application Layer Controls
The application layer is where most of the practical work to secure AI agents actually happens. Input validation should filter and flag known injection patterns and suspicious instruction formats before they ever reach the model. Output verification should run on every AI response before it is executed or displayed, catching sensitive data leakage and flagging anomalous behavior early.
Sandboxed tool execution is critical for agents with real-world capabilities. If an agent has access to shell commands, file systems, payment APIs, or email systems, those tools need to run inside isolated containers with scoped credentials and minimal permissions. Human confirmation gates should be required for any high-impact, irreversible action regardless of what the agent has been instructed to do on its own.
One particularly effective application-layer pattern is the guardian model approach: a secondary AI model evaluates the primary agent’s planned actions before execution, flagging anything that deviates from the original user intent or system policy. This dual-model check adds latency, but it substantially reduces the risk of an injected instruction executing at full scope.
Context and Retrieval Layer Security
RAG systems introduce a specific injection surface called retrieval poisoning. Research published in January 2026 found that just five carefully crafted documents can manipulate AI responses 90 percent of the time when they enter the agent’s context through a retrieval pipeline. Defending this surface requires retrieval-time access control, provenance tracking for all retrieved content, and zero-trust authentication between agent components. For teams building retrieval-augmented agents, this layer often gets the least attention while carrying the most risk.
Metadata governance matters here too. Every document or data source an agent retrieves should carry verifiable provenance. If an agent cannot confirm where content came from, that content should be treated as untrusted and processed with additional scrutiny before being acted upon. This is a foundational requirement for teams that need to genuinely secure AI agents operating in open environments.
Infrastructure and Monitoring
Behavioral monitoring is the most important detection mechanism teams use to secure AI agents against attacks that slip past other layers. Log every tool call, every retrieval operation, and every decision point the agent makes. Feed those logs into your existing SIEM or SOAR platform. Current industry guidance recommends targeting attack detection within 15 minutes and automated containment within five minutes as baseline benchmarks for teams securing AI agents in regulated environments.
For teams deploying agents across multiple applications, AI gateway tools operating at the infrastructure layer can enforce input and output guardrails without requiring any changes to application code. These gateways intercept every prompt before it reaches the model provider and inspect every response before it reaches the caller, giving security teams a centralized control point across an entire agent fleet.
If you are still in the early stages of building your agent infrastructure, understanding how architectural decisions affect your security surface is essential. The developer’s guide to building custom AI agents covers the trade-offs between low-code and full-stack approaches that directly affect how much attack surface you expose from day one.
Real-World Use Cases
A financial services firm discovered in early 2026 that its customer-facing AI agent had been leaking internal pricing data for three weeks through a prompt injection attack that overrode its system prompt. No buffer overflow, no SQL injection, no misconfigured API. The attacker had simply submitted carefully constructed questions that caused the agent to ignore its confidentiality instructions entirely.
On the defensive side, a multinational bank deployed layered prompt injection defenses across its AI-powered fraud detection system and prevented 18 million dollars in potential losses from manipulated transaction approvals, while maintaining 99.7 percent legitimate transaction throughput. A hospital network worked to secure AI agents powering its clinical decision support system, keeping HIPAA compliance intact while letting physicians query patient records through natural language interfaces and improving diagnostic efficiency by 34 percent.
These examples confirm that the impact of a sound secure AI agents architecture is measurable, and the cost of getting security wrong is immediate and financially significant.
Identity and Access Control: A Critical Gap When You Secure AI Agents
One of the most underestimated dimensions of securing AI agents is identity management. A 2026 industry survey found that only 18 percent of organizations were confident their current identity and access management systems could handle agent identities. Meanwhile, 40 percent already run agents in production. That gap represents a large population of deployments operating without adequate controls in place.
Agents must be treated as non-human identities subject to the same rigor applied to human users. That means token-based authentication, dynamic authorization policies scoped to specific tasks, regular credential rotation, and full audit trails covering every action taken under a given agent identity. The OWASP Top 10 for Agentic Applications 2026 specifically identifies identity and privilege abuse as one of the ten most critical risks. Treating agent identity as a secondary concern is itself a structural vulnerability.
For custom AI agent development, this means IAM architecture should be designed before tool integrations are built. The permission scope of each tool call should be defined as part of the agent’s specification, not tacked on after the fact. An agent with write access to a production database should go through the same level of access review as a human engineer with equivalent permissions.
Expert Analysis
The defining challenge of how to secure AI agents in production is that the attack surface is semantic, not syntactic. Traditional security controls inspect packets, filter URLs, and scan binary signatures. None of that is relevant when the attack vector is a naturally worded sentence embedded inside a web page that an agent reads in the course of doing its job.
This structural reality has two important implications for developers and security teams working on prompt injection prevention. First, security cannot be bolted onto an agent deployment after the fact. It has to be designed into the agent’s architecture from the beginning, covering model selection, tool scoping, retrieval governance, identity management, and behavioral monitoring before the first line of application code is written. Second, the goal cannot be perfect prevention. The research consensus in 2026 is clear: prompt injection will not be fully solved within current LLM architectures. The International AI Safety Report 2026 found that sophisticated attackers bypass best-defended models approximately 50 percent of the time with just ten attempts.
What this means practically is that your security model should assume compromise is possible and be designed to contain it. Scoped credentials limit what injected instructions can access. Sandboxed tools limit what they can execute. Human confirmation gates limit what actions they can trigger. Behavioral monitoring ensures detection before effects become irreversible. Defense frameworks implemented correctly across all layers reduce attack success rates from over 73 percent to under 9 percent. That is a consequential margin, even if achieving zero successful attacks is not realistic with current technology.
The organizations that avoided incidents in Q2 2026 largely share one characteristic: they deployed agents progressively, starting with limited-scope implementations, verifying behavior under adversarial conditions, and only expanding tool access and autonomy after those checks passed. That progressive deployment discipline is currently the most effective operational control available to teams that need to secure AI agents without waiting for the field to produce a complete technical solution. No vendor contract required. Just architectural discipline applied consistently from the start.
Future Outlook
The OWASP agentic security framework is explicitly described as a living document. Multi-agent pipelines, Model Context Protocol tool integrations, and agents with persistent cross-session memory will introduce new attack surfaces that current frameworks do not fully anticipate. Structured output parsing, dual-stage gateway guardrails, and model-level architectural changes designed to separate instruction processing from data processing are the areas receiving the most active research investment heading into the second half of 2026.
The regulatory environment is tightening in parallel. The EU AI Act reaches full enforcement in August 2026. NIST’s AI Agent Standards Initiative is developing binding guidance through CAISI. ISO 42001 already mandates specific controls for prompt injection prevention and detection. For teams in regulated industries, the question of how to secure AI agents is shifting from optional best practice to mandatory compliance requirement within the current fiscal year. The OWASP Agentic Security Initiative maintains the most current public guidance and is updated as the threat landscape evolves.
For teams building in 2026, the practical recommendation is straightforward: implement the layered defense framework now, run quarterly red team exercises using the OWASP ASI framework as your threat model, and monitor updates from NIST, OWASP, and your model providers continuously. The threat landscape will evolve faster than any previous cybersecurity category, because the agents being attacked are themselves becoming more capable with every model generation.
Conclusion
The pace at which AI agents are entering production has outrun the pace at which security teams have built frameworks to govern them. Prompt injection is not a theoretical research problem. It is the defining attack category of the agentic AI era, and the data from 2026 confirms it is being actively exploited at scale. To genuinely secure AI agents in production requires a layered architecture combining model-level resistance, application controls, context governance, agent identity management, and behavioral monitoring. No single control is sufficient on its own. The combination is what reduces a successful injection from catastrophic to contained. Start with the OWASP Agentic Security framework, apply least-privilege principles to every tool your agents can access, and build behavioral monitoring before you scale. That is the practical foundation for deploying secure AI agents that hold up against the real attack landscape of 2026.
Frequently Asked Questions
Indirect prompt injection is currently the most prevalent and most dangerous form. In this attack, malicious instructions are hidden inside external content such as web pages, emails, or documents that the agent retrieves during normal operation. The attacker never needs direct access to the AI interface, which makes this attack harder to detect and attribute than direct injection attempts.
Use the OWASP Top 10 for Agentic Applications 2026 as your primary threat model. Red teaming tools designed for LLM systems let you run structured adversarial assessments at the model reasoning level. For infrastructure-level testing, run quarterly exercises that include direct and indirect injection scenarios, tool abuse attempts, and memory poisoning simulations against your production configuration.
No. The research consensus in 2026 is that prompt injection cannot be fully eliminated within current LLM architectures. That said, layered defenses reduce attack success rates dramatically, from above 73 percent on undefended systems to under 9 percent on well-defended ones. The goal of prompt injection prevention is not zero attacks but a controlled, recoverable impact when attacks do land.
Agents should follow the principle of least privilege. Grant only the specific tool access, API scopes, and data permissions required for each defined task. Use scoped credentials, enforce human confirmation for irreversible actions, and rotate agent credentials regularly. Treat agents as non-human identities with full IAM governance applied from the start of custom AI agent development.
The primary frameworks are the OWASP Top 10 for Agentic Applications 2026, NIST’s AI Risk Management Framework, and the EU AI Act, which reaches full enforcement in August 2026. ISO 42001 also mandates specific controls for prompt injection prevention and detection. For regulated industries, compliance with these frameworks is becoming mandatory rather than advisory.